Azure Data Factory and REST APIs – Mapping and Pagination
In this blog post I would like to put a light on a mapping and pagination of a Copy activity which are often are requirements for the ingestion of REST data.
Mapping is optional for data sources, like relational databases, parquet or csv files, because the incoming dataset contains an inherited structure, so the Data Factory is smart enough to pick it up and set as a default mapping.
However, to ingest hierarchical data like JSON or REST and then load it in as a tabular format an explicit schema mapping is required. In the previous blog post – Azure Data Factory and REST APIs – Setting up a Copy activity – such mapping was not provided yet explicitly. As a result, ADF was not able to write an incoming data streams in a tabular form and created an empty csv file. This post will fill such gap. Also, it will cover pagination which is also a common thing for REST APIs.
Prerequisites
- REST API Data source. I use Exact Online SaaS service in this post as an example.
- Azure Storage account.
Mapping of hierarchical data
Mapping can be configured in a few various ways:
- Fully manual, by adding mapping columns one by one
- Automatic, by importing schema from a data source
In this post I will describe a second approach – import of schema. This is a straightforward action and can be achieved by opening a tab “Mapping” and clicking on “Import Schemas”, just like on a picture:

However, because the current example uses oauth2, there is one prerequisite that must be fulfilled – bearer token to be passed on a design time. This token is necessary to get authenticated during schema import, just because Azure Data Factory makes a call to API to get a sample data for further parsing and extraction of the schema. Because of this, following window will popup and it expects token to be entered:
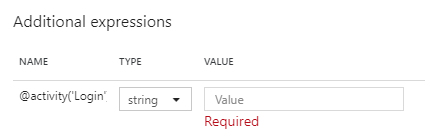
Step 1: Retrieve a bearer token
To obtain the access token run a debug execution (1) and copy it from an output window (2) of a Login activity.
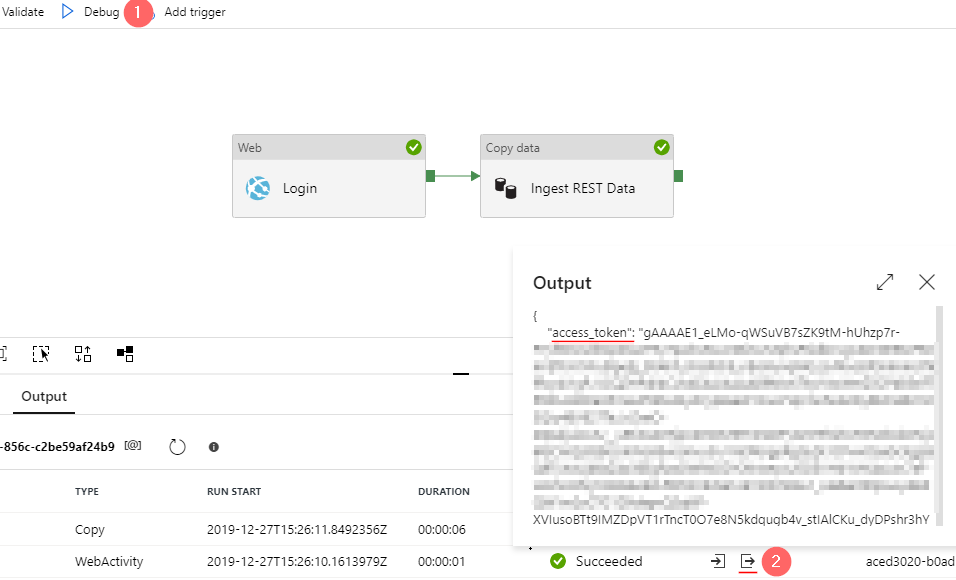
Step 2: Import schema
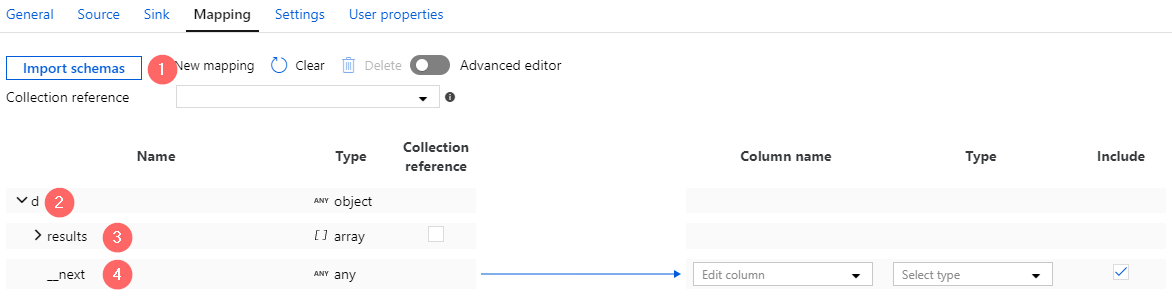
When the token is copied to a clipboard click on “Import schemas” again, paste the token in a popup window. As the result, the schema of a hierarchical format is imported. In the current example it contains:
- A Root element –
d(2) - A collection of items –
results(3) - A string value
__next(4) that holds a URL to another page. Later this value will be used for a pagination
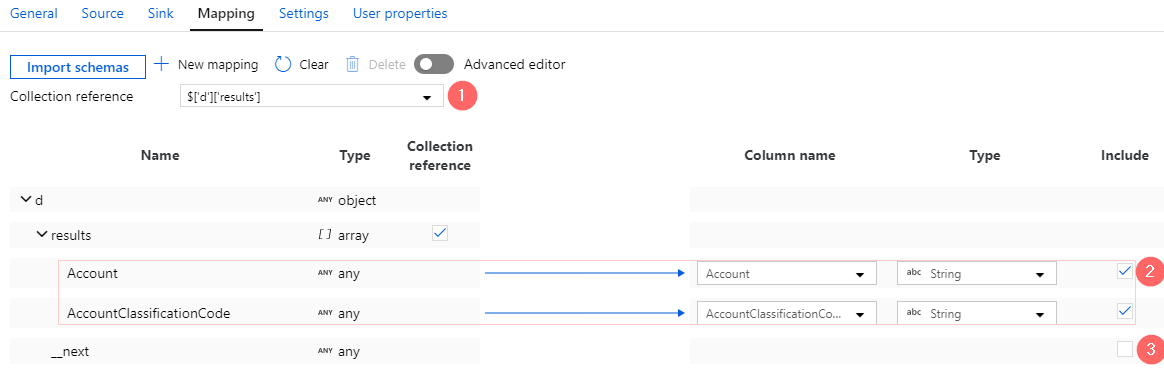
Step 3: Adjust mapping settings
As soon as schema imported a few more things to be finalized:
- Set a collection reference (1): a JSON path to an enumaration of all rows. In our case it is:
$['d']['results'] - Expand the node
resultsand remove columns that do not have to be imported (3). - Exclude value
__nextfrom the mapping, it should not be included in the final export (4).
Step 4. Run a test execution
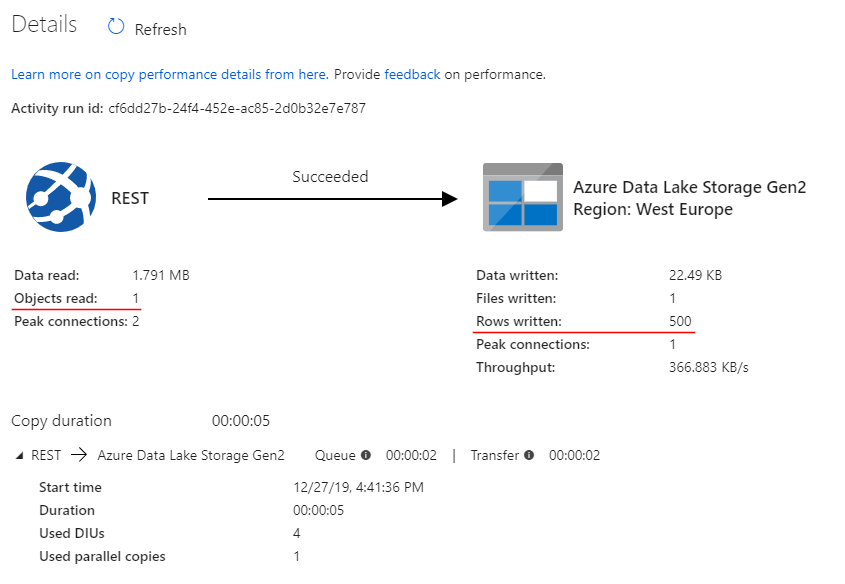
This time Copy activity loads 22 kb of data or 500 rows which is a right step forward:
However, the data source contains way more than 500 rows and the details page shows that only one object was read during fetching from API. This means that only a single page was processed:
Setting up a pagination
Normally, REST API limits its response size of a single request under a reasonable number; while to return large amounts of data, it splits the result into multiple pages and requires callers to send consecutive requests to get the next page of the result. Therefore, to get all rows pagination to be configured for a source data store.
Step 1. Configure pagination rule
- Open a Source Tab of a Copy activity, navigate to “Pagination Rules” and click on “+ New”
- Add a pagination rule:
- Name:
AbsoluteUrl - Value:
$.d.__next
- Name:

Step 2. Run another test execution
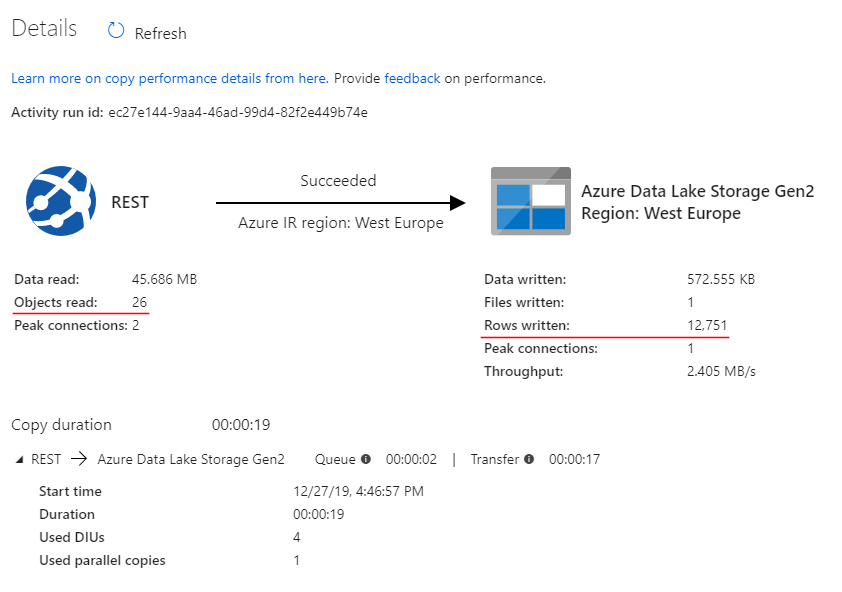
A second execution shows more realistic stats – 26 REST API calls (or pages) loaded into 12751 rows:
Final words
The second piece of the pipeline – a Copy activity now is finally looking complete. It does not just establishes connections with a REST data source, also it fetches all expected rows and transforms them from a hierarchical into a tabular format.
In the next post of the series – Azure Data Factory and REST APIs – Managing Pipeline Secrets by a Key Vault – is a time to touch another important aspect – security and a management of sensitive data like client secrets or passwords.
Many thanks for reading.